Hadoop-HA高可用搭建教程
Hadoop-HA高可用搭建教程
1.Hadoop-HA工作原理
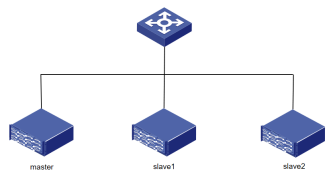
实验室场景下的Hadoop集群,通常是一主节点多从节点的模式,其架构如图所示:
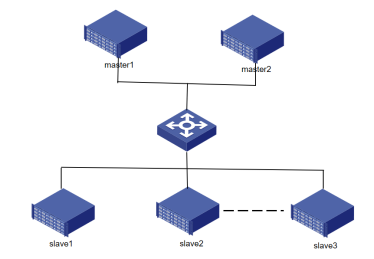
然而在实际生产场景中,为了尽可能保证集群的可靠性,通常会对名称节点进行热备份。备份的方式是通过Zookeeper进行热备份,一旦检测到主节点失效,会立即启用热备份的名称节点:
Hadoop-HA(High Availablity)分为HDFS高可用和YARN高可用,两者的实现基本类似,但是HDFS Namenode对数据存储及其一致性的要求要比Yarn Resourcemanager要高得多,因此实现会更加复杂一些。以下是Hadoop-HA的架构图:
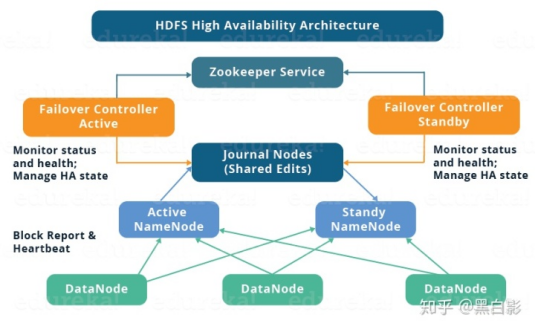
Hadoop-HA包含以下组件:
(1)Active Namenode和Standby Namenode形成互相备份,Active Namenode为主名称节点,Standby Namenode为备份名称节点,只有Active Namenode才能对外提供读写服务。
(2)主备切换控制器ZKFailoverController:ZKFailoverController是独立运行的进程,对Namenode的主备切换进行总体控制。ZKFailoverController能够及时检测Namenode的健康状态,在主名称节点故障时借助Zookeeper实现自动主备选举和切换,Namenode也支持进行手动的主备切换。
(3)Zookeeper集群:为主备切换控制器提供主备选举支持。
共享存储系统:共享存储系统是实现Namenode的高可用的最为关键的部分,共享存储系统保存了Namenode在运行过程中所产生的HDFS的元数据。主备Namenode通过共享存储系统实现元数据同步。在进行主备切换时,新的主Namenode在确认元数据备份完成后才能继续对外提供服务。
(4)DataNode节点:除了通过共享存储系统共享HDFS的元数据信息以外,主备Namenode还需要共享HDFS数据块和Datanode之间的映射关系,DataNode会同时向主Namenode和备Namenode上报数据块的位置信息。
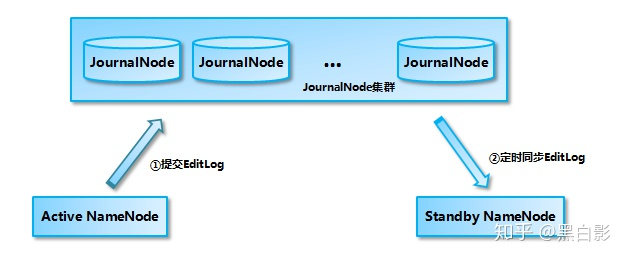
目前Hadoop支持Quorum Journal Manger(QJM)或者Network File System(NFS)作为共享存储系统,以QJM为例:Active Namenode首先把EditLog提交到JournalNode集群,然后Standby Namenode再从Journal Node集群定时同步 EditLog,当 Active NameNode 宕机后, Standby NameNode 在确认元数据完全同步之后就可以对外提供服务。
需要说明的是向 JournalNode 集群写入 EditLog 是遵循 “过半写入则成功” 的策略,所以你至少要有 3 个 JournalNode 节点,当然你也可以继续增加节点数量,但是应该保证节点总数是奇数。同时如果有 2N+1 台 JournalNode,那么根据过半写的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。