Hadoop全分布式搭建教程
1.HADOOP的下载
Hadoop3.3.6官方 下载地址
JDK8u221官方 下载地址
2.集群规划
| 主机名称 |
主机 IP地址 |
进程 |
| master |
192.168.xxx.101 |
namenode、secondarynamenodde、resourcemanager |
| slave1 |
192.168.xxx.102 |
datanode、nodemanager |
| slave2 |
192.168.xxx.103 |
datanode、nodemanager |
3.安装虚拟机
(1)选择稍后安装操作系统
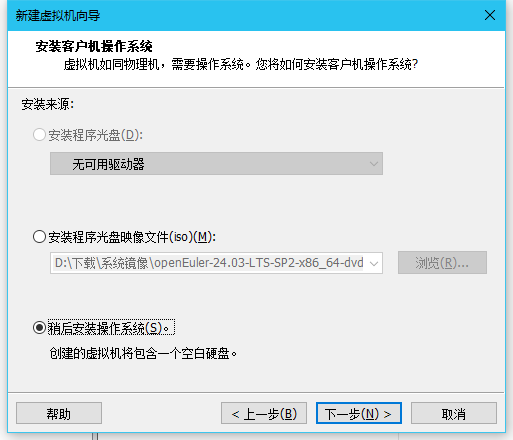
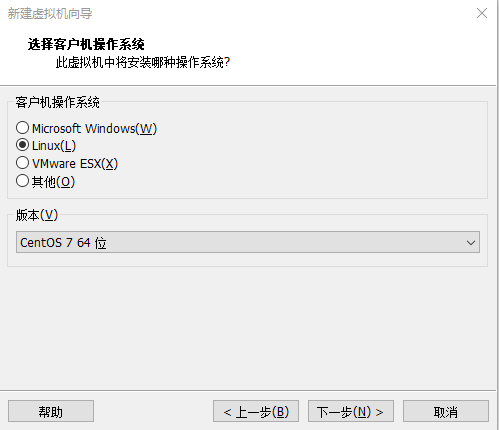
(2)操作系统选择Linux,版本选择CentOS 7 64位
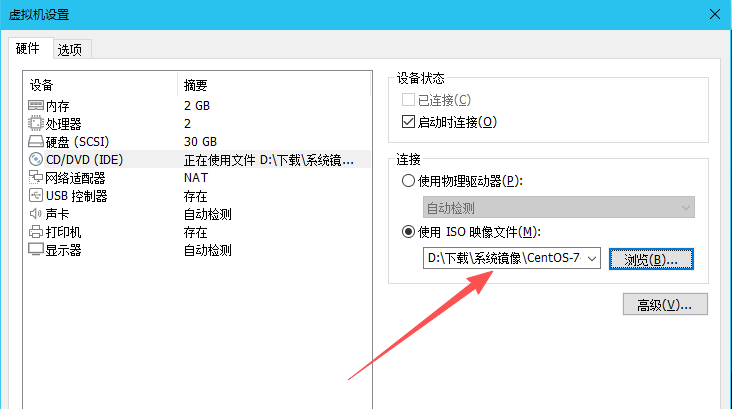
(3)选择操作系统镜像
(4)设置安装位置
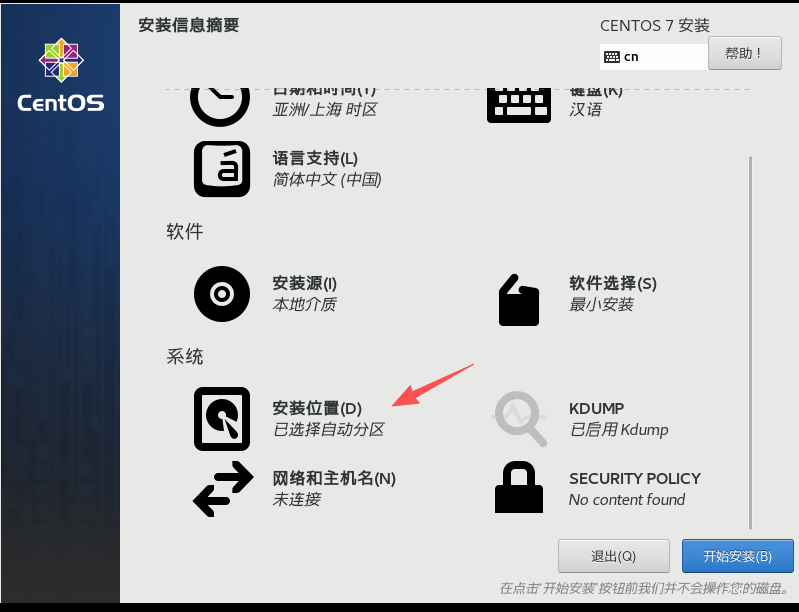
(5)手动配置分区
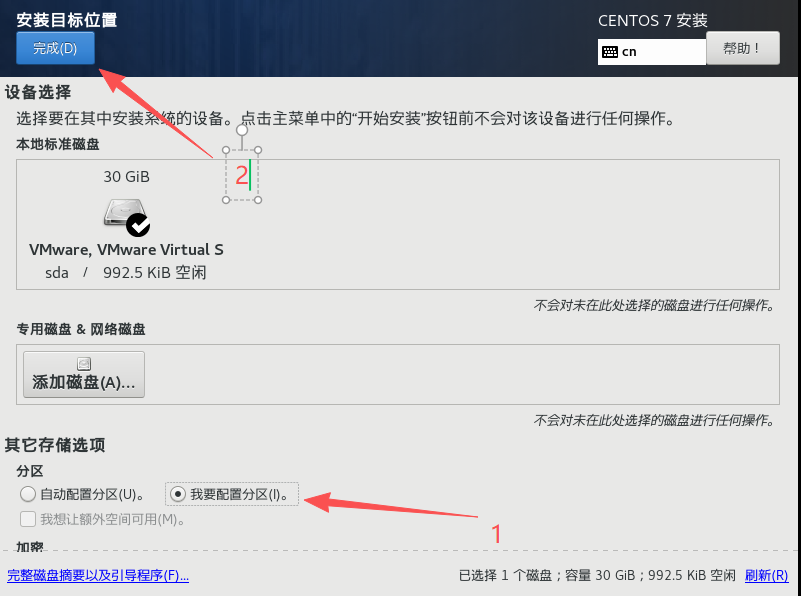
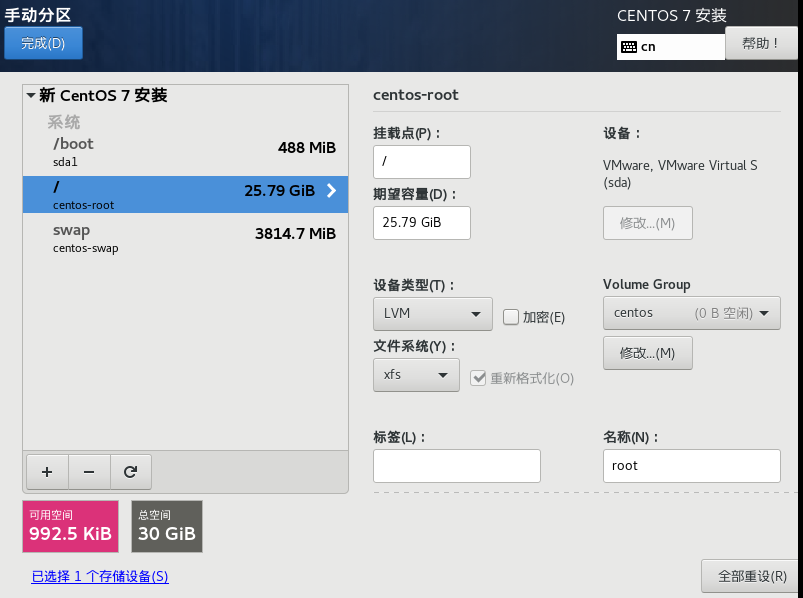
①添加swap分区,大小设置为物理内存大小的1-2倍;
②添加/boot分区,该分区用于引导操作系统启动,大小设置为512MB左右;
③添加/分区,该分区用作操作系统的文件系统,剩余空间都分配给根目录。
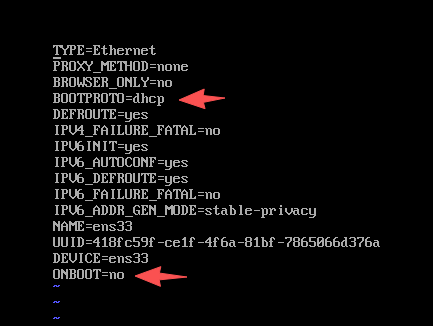
(6)配置虚拟机的网卡文件
①虚拟机的 网卡文件存放在/etc/sysconfig/network-scripts路径下,默认情况下该文件名称为ifcfg-ens33
1
| vi /etc/sysconfig/network-scripts/ifcfg-ens33
|

通过Vmware Workstation的虚拟网络编辑器查看虚拟网卡的IP网段
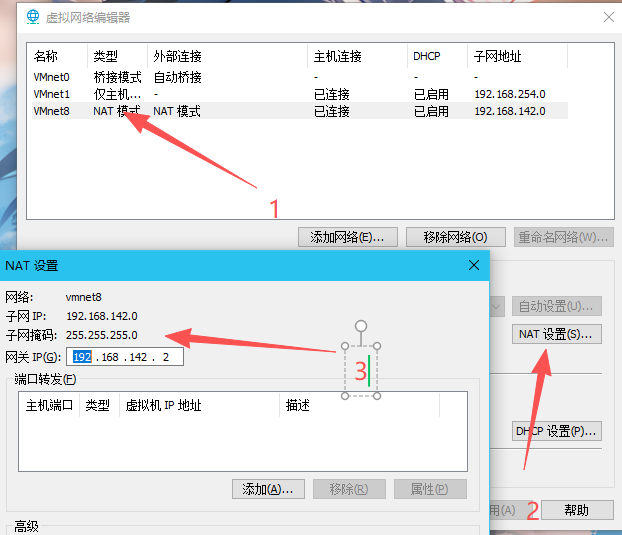
修改网卡配置文件
1
2
3
4
5
6
| 将 BOOTPROTO修改为static
将 ONBOOT修改为yes
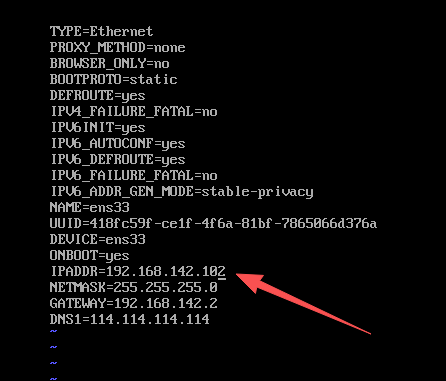
IPADDR=192.168.142.101
NETMASK=255.255.255.0
GATEWAY=192.168.142.2
DNS1=114.114.114.114
|
重启网卡
1
| systemctl restart network
|
测试网络连通性
看到如下内容就说明,网卡配置好了。

(7)使用mobaxterm远程连接服务器

(8)创建工作目录
1
| mkdir /opt/data /opt/module /opt/software
|
将jdk与hadoop的压缩包上传至/optsoftware
(9)关闭并禁用防火墙
1
2
| systemctl stop firewalld
systemctl disable firewalld
|

(10)修改主机名称与ip地址映射关系

(11)解压Hadoop与JDK
1
2
| tar -zxf jdk-8u221-linux-x64.tar.gz -C /opt/module
tar -zxf hadoop-3.3.6.tar.gz -C /opt/module
|

(12)配置环境变量
1
2
3
4
5
6
7
8
9
10
| vi /etc/profile
# 在文末添加以下内容
export JAVA_HOME=/opt/module/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=$PATH:HADOOP_HOME/bin
export PATH=$PATH:HADOOP_HOME/sbin
# 保存后刷新环境变量
source /etc/profile
|

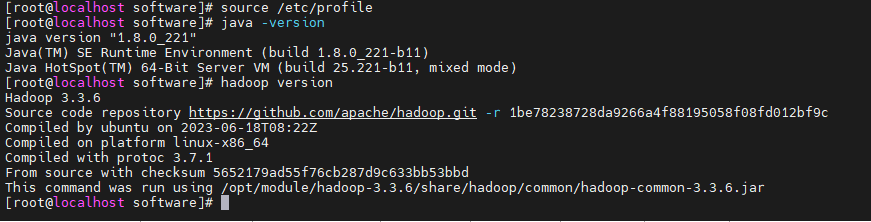
验证JDK与Hadoop是否安装成功
1
2
| java -version
hadoop version
|
(13)克隆两台主机,并修改IP地址
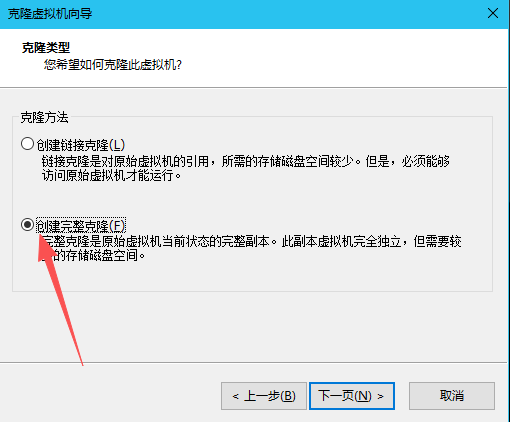
分别修改slave1和slave2的IP地址
(14)修改主机名称
1
2
3
4
5
6
7
| # 分别三台主机执行
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
# 刷新
bash
|

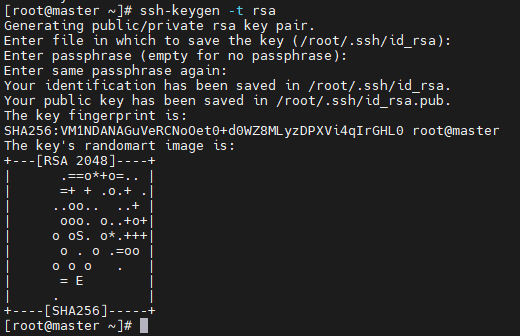
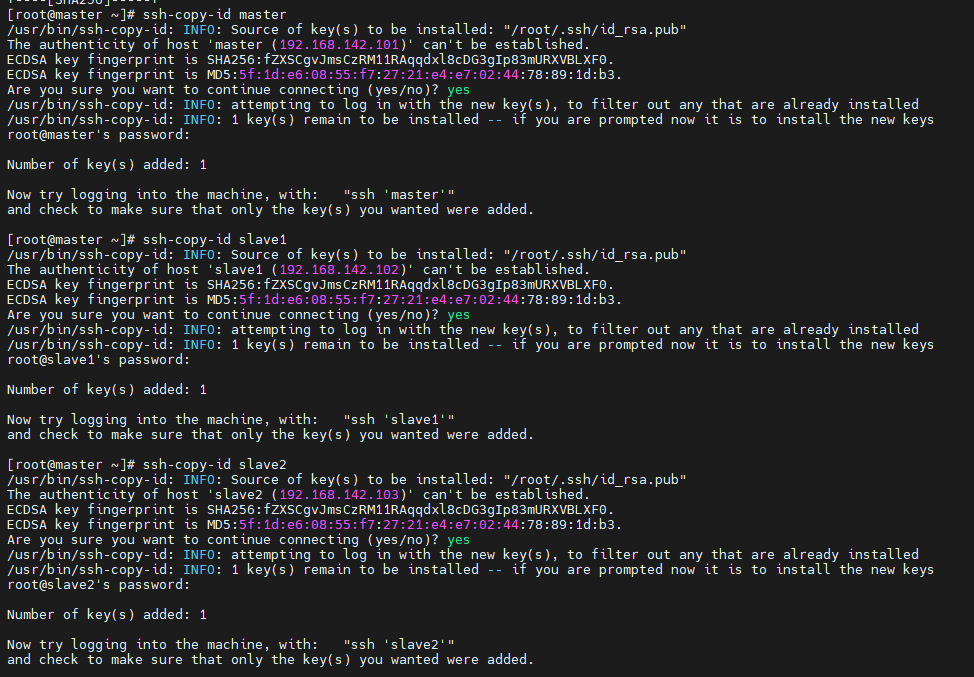
(15)配置免密登录
分别在三台主机执行以下步骤
1
2
3
4
5
6
| # 连续四次回车完成密钥生成
ssh-keygen -t rsa
# 将密钥发送给三台主机
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
|
(16)配置Hadoop的配置文件
1
| cd $HADOOP_HOME/etc/hadoop
|
①配置hadoop-env.sh
1
2
3
4
5
6
7
8
9
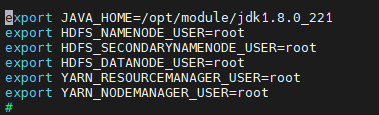
| vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_221
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
|
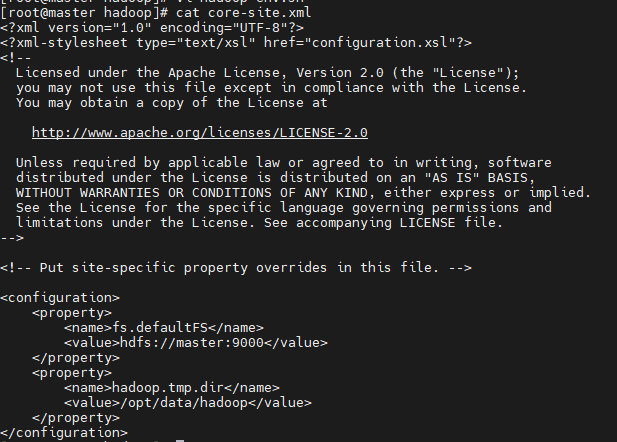
②配置core-site.xml
1
2
3
4
5
6
7
8
9
10
11
| #在<configuration></configuration>中添加以下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop</value>
</property>
</configuration>
|
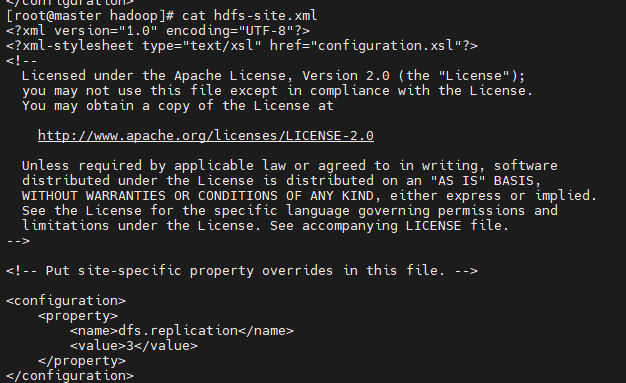
③配置hdfs-site.xml
1
2
3
4
5
6
| <configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
|
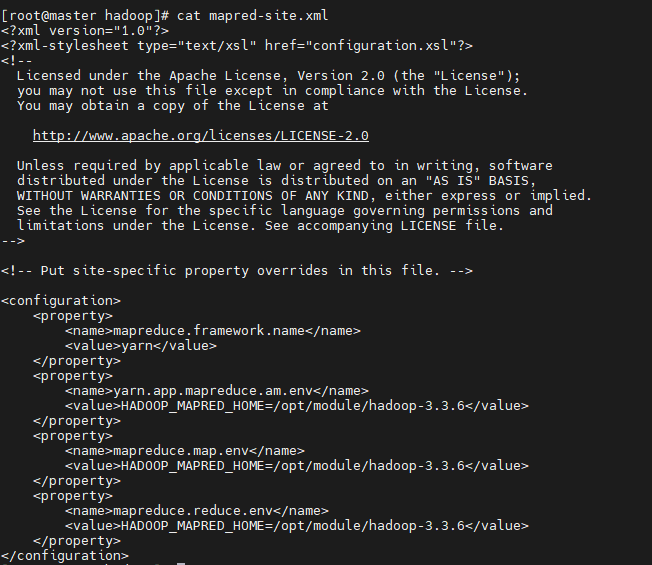
④配置mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.6</value>
</property>
</configuration>
|
⑤配置yarn-site.xml
1
2
3
4
5
6
7
| <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
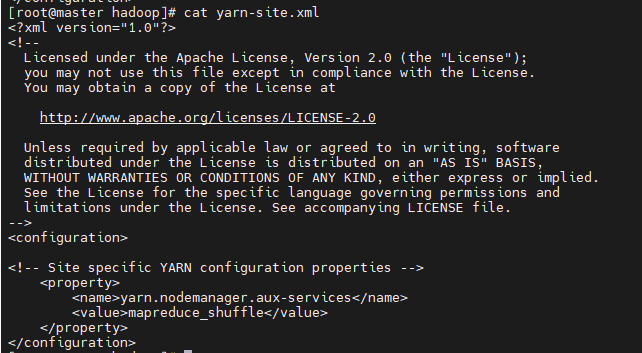
⑥配置workers

将配置文件分发至slave1与slave2
1
2
| scp -r $HADOOP_HOME/etc/hadoop root@slave1:/opt/module/hadoop-3.3.6/etc/
scp -r $HADOOP_HOME/etc/hadoop root@slave2:/opt/module/hadoop-3.3.6/etc/
|
(17)格式化名称节点
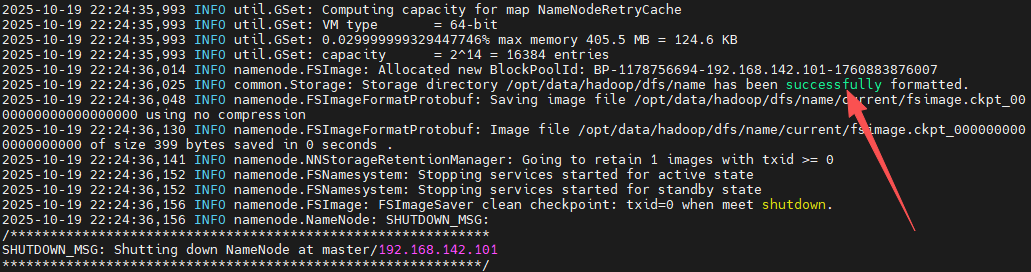
看到图中successfully的提示信息就说明格式化成功了。
(18)启动集群
1
2
3
4
5
6
7
8
| # 群起群停
start-all.sh
stop-all.sh
# 单独启停
start-dfs.sh
start-yarn.sh
stop-dfs.sh
stop-yarn.sh
|
在master上能看到以下进程:
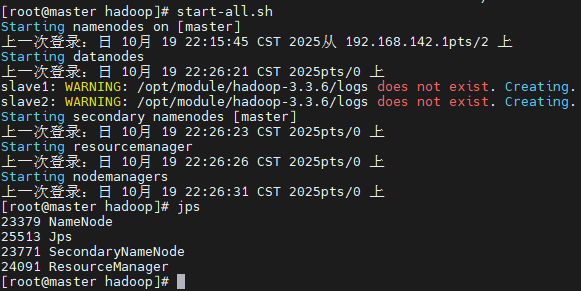
在slave节点上能看到以下进程:

至此Hadoop集群完全分布式搭建完毕!
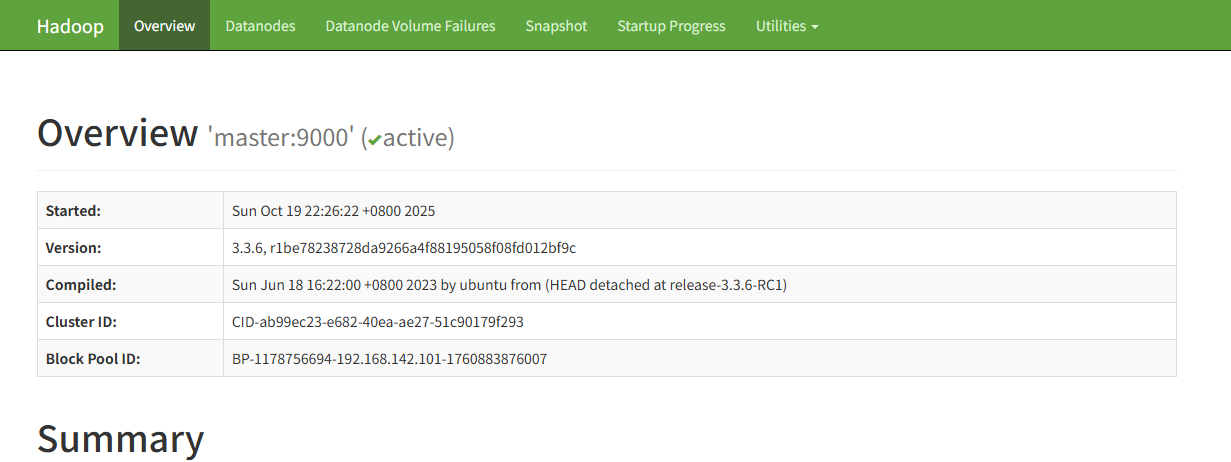
(19)查看HDFS与YARN可视化界面:
1
2
3
4
| # 查看HDFS可视化界面
192.168.142.101:9870
# 查看YARN可视化界面
192.168.142.101:8088
|